
ENTRETIEN AVEC CHAHAN VIDAL-GORÈNE, FONDATEUR DE CALFA
Dans vos archives vous avez des papiers de famille écrits en arménien ou dans une langue orientale difficile à déchiffrer à cause de leur graphie ancienne? Vous avez tellement envie de comprendre ces textes qui pourraient contenir des informations sur vos aïeux mais les spécialistes du domaine ne courent pas les rues. Alors, que faire?
Depuis quelques années, CALFA, une association basée à Paris, développe une technologie qui permet d’extraire des informations de manuscrits anciens et d’archives manuscrites scannés. Artzakank a rencontré Chahan Vidal-Gorène*, président et fondateur de Calfa, pour mieux comprendre les solutions numériques que l’association propose pour les langues orientales.
***
Artzakank: Pourriez-vous présenter Calfa et expliquer comment l’idée de lancer un tel projet est née?
Chahan Vidal-Gorène: Calfa est une association spécialisée dans le traitement automatique des langues orientales, en particulier l’arménien, et l’analyse automatique de documents. Cela comprend la reconnaissance de textes manuscrits et l’extraction d’informations clefs dans des documents, avec l’utilisation d’intelligence artificielle. Les systèmes que nous développons sont tout d’abord destinés à des professionnels, publics ou privés, du patrimoine, ou engagés dans la numérisation de documents et de collections et qui souhaitent en rendre accessible et compréhensible le contenu.
L’histoire de Calfa remonte à 2014. À l’origine, il s’agissait de créer un dictionnaire en ligne d’arménien classique-français. En cours d’arménien classique à l’INALCO (Institut National de Langues et Civilisations Orientales) notre support de travail a été le Dictionnaire arménien-français d’Ambroise Calfa, un ouvrage de référence pour l’étude de l’arménien classique, et j’ai eu la chance d’en acquérir le dernier exemplaire dont disposait la librairie Samuelian. Constatant la difficulté de trouver des ressources papier pour l’étude de l’arménien classique, je me suis lancé avec un groupe d’étudiants de ma promotion et une professeur, Agnès Ouzounian, à la création d’une copie numérique de ce dictionnaire, d’où le nom de notre association. Avec le soutien de la Fondation Calouste Gulbenkian et de la Fondation des Frères Ghoukassiantz de Genève, nous avons progressivement ajouté d’autres dictionnaires pour faire du site calfa.fr la référence la plus complète en lexicographie arménienne classique.
Globalement, le travail de numérisation du premier dictionnaire a été fait manuellement mais pour les suivants nous avons utilisé les solutions OCR (Optical Character Recognition) de l’époque et nous sommes rendu compte qu’elles n’étaient pas adaptées pour ce genre de documents en arménien classique avec une typographie à l’ancienne et des pages parfois endommagées. C’est à partir de 2016 que notre équipe s’est penchée sur le développement d’une technologie intelligente de reconnaissance de caractères, d’abord pour les imprimés puis pour les manuscrits arméniens.

A.Quelles ont été les différentes étapes de développement de l’expertise de Calfa en reconnaissance de textes et en numérisation?
Ch. V-G.: En 2016-17, grâce à un financement de la Fondation Gulbenkian, nous avons effectué un important travail de prospection en vue de réaliser une recherche et développement pour l’OCR des manuscrits. Cela coïncide avec l’essor de l’intelligence artificielle en général et la grande dynamique de numérisation de documents en cours dans le monde occidental. Les bibliothèques et les institutions se sont lancées dans la numérisation de leurs collections et archives. Ainsi, les fonds sont certes préservés et mis en ligne mais la recherche d’informations avec un ordinateur nécessite autant de temps que manuellement sur un support papier. En ce qui concerne les textes en arménien classique, même si ce patrimoine était théoriquement devenu accessible, il faut en plus avoir des compétences linguistiques et paléographiques pour accéder au contenu. Nous avons alors pensé à développer une solution pour permettre aux personnes qui n’ont pas ces compétences d’accéder aux informations contenus dans les documents numérisés.
C’est dans cet esprit que nous avons commencé à construire notre technologie et après une période d’expérimentation, nous avons abouti à une première technologie exploitable et assez pertinente. Nous avons commencé par des imprimés simples sans mise en page particulière. Puis, nous avons amélioré la technologie pour pouvoir gérer les journaux avec des répartitions de contenu beaucoup plus complexe pour arriver aux manuscrits anciens. Une fois les écueils techniques surmontés, nous avons commencé à nous intéresser à des archives manuscrites plus complexes en termes de graphie compte tenu de la variété des mains et de la grande cursivité des écritures.
Entre 2016 et 2020-21, grâce à nos partenariats avec différentes institutions nous avons renforcé notre technologie de reconnaissance de caractères pour obtenir des modèles qui ont une très grande capacité à traiter une variété de documents, de graphies et de périodes.
Aujourd’hui, notre expertise nous conduit à extraire de nombreux niveaux d’informations et de les structurer selon les besoins d’un projet de recherche ou éditorial. Nous produisons bien sûr de simples textes, mais aussi par exemple des bases de données morphologiquement analysées pour la comparaison linguistique de texte (en partenariat notamment avec l’équipe GREgORI de Louvain-la-Neuve), des catalogues numériques ou des bases de textes dans lesquelles sont identifiés certaines informations clefs comme des dates de publication, des noms d’auteurs, etc., voire même la classification d’images dans des journaux, tout traitement sur-mesure qui permet d’augmenter l’accessibilité et l’exploitation des documents. Cela est très variable selon les besoins.
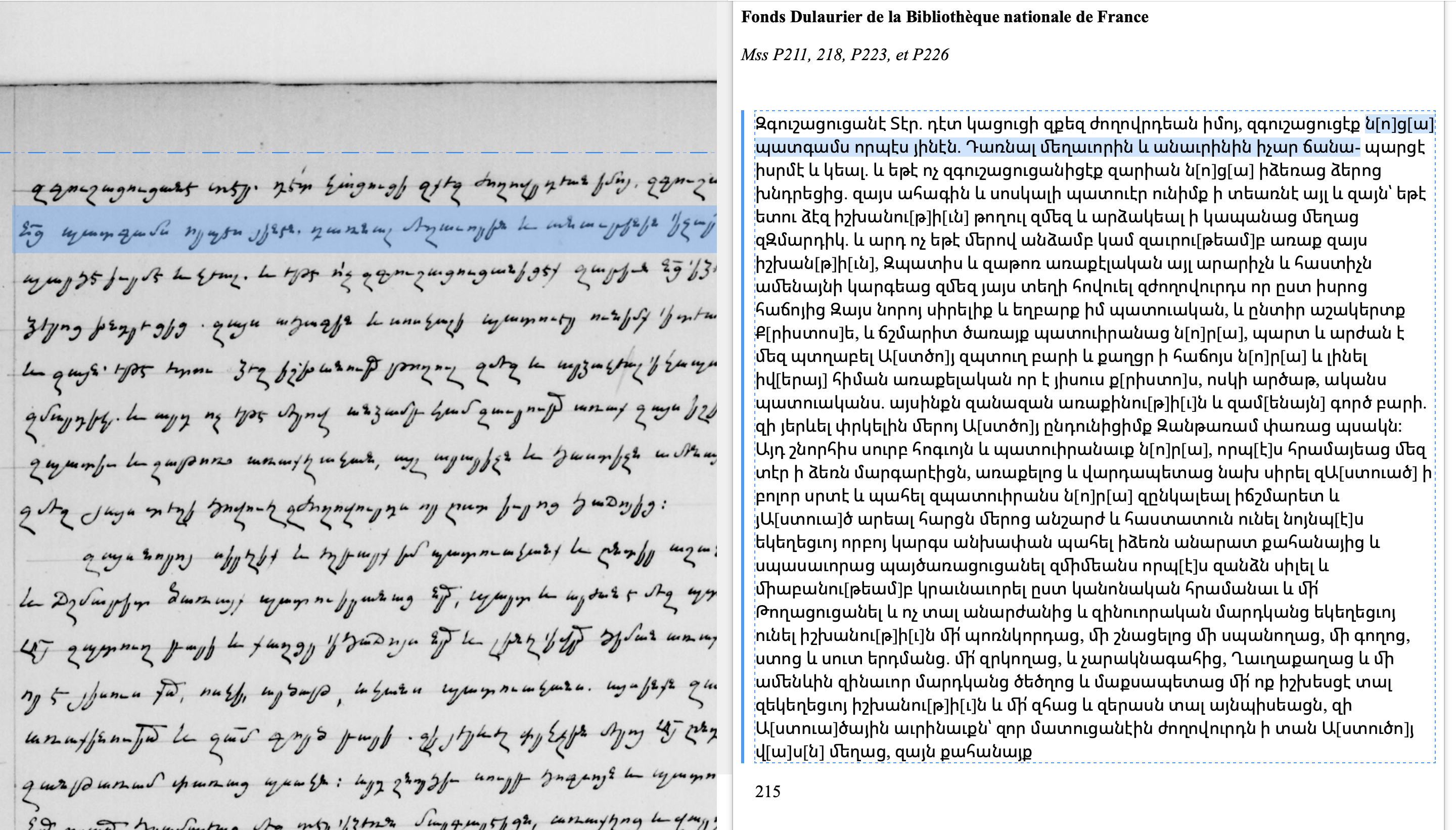
(Fonds Dulaurier)
A. Que pouvez vous dire de l’équipe de Calfa et de ses partenariats?
Ch. V.-G.: Notre équipe de 13 personnes est composée de doctorants et ingénieurs en intelligence artificielle et en développement de logiciels mais aussi de philologues et linguistes. C’est peut-être une des originalités de Calfa; nous ne misons pas uniquement sur l’apport massif de données, comme cela se fait classiquement dans le domaine de l’intelligence artificielle pour surmonter un problème, mais travaillons spécifiquement sur la langue cible pour créer des jeux de données très réduits mais très qualitatifs. Nous collaborons avec des doctorants ou des jeunes chercheurs qui travaillent avec des manuscrits au quotidien et qui nous permettent de surmonter les difficultés paléographiques et philologiques.
Nous portons également des projets de recherche communs avec des laboratoires ou des institutions patrimoniales pour surmonter cette question de la reconnaissance de textes manuscrits pour de nouvelles langues que nous ne maîtrisons pas en interne. C’est par exemple le cas sur l’arabe maghrébi où nous avons intensément collaboré avec le GIS MOMM, l’agora DISTAM et la BULAC et qui ont donné lieu à la création de modèles et de jeux de données pour les manuscrits maghrébins.
Parmi nos partenariats ces dernières années, je peux citer le Matenadaran (Institut Mashtots de recherches sur les manuscrits anciens) et la Fundamental Scientific Library de l’Académie nationale des sciences d’Arménie, à Erevan, la BULAC (Bibliothèque Universitaire des Langues et Civilisations) et la Bibiliothèque Nubar à Paris, ou encore la Congrégation Mkhitariste à Venise, partenaires avec qui nous réalisons soit des échanges scientifiques (p. ex. échange d’expertise philologique pour le traitement d’archives arméniennes) soit menons des projets de numérisation de leurs collections.

(Fonds Congrégation Mkhitariste)
A. Quelles sont les autres langues que vous traitez?
Ch. V.-G.: Calfa se concentre sur les langues orientales qui ne sont pas couvertes efficacement par les outils grand public. Nous proposons nos services pour n’importe quelle langue peu dotée, le système étant adaptable et entraînable très rapidement.
Actuellement, en partenariat avec la BULAC, nous travaillons sur l’OCR-isation de 60’000 documents chinois xylographiés du Collège de France, de la Bibliothèque Nationale et Universitaire de Strasbourg et de la BULAC.
Nous venons de terminer un gros projet avec la BULAC sur une cinquantaine de documents manuscrits et lithographiés arabes sur l’histoire du Maghreb. Après contrôle, ils seront mis en ligne sur le site de la bibliothèque numérique de la BULAC.
Parmi les autres langues que nous avons traitées à ce jour, je peux citer le persan, le géorgien, ancien et moderne, le syriaque, l’hébreu, l’éthiopien et le grec byzantin.
A. À qui s’adresse la technologie de Calfa et concrètement comment les personnes intéressées pourraient-elles y accéder?
Ch. V.G.: Nos services s’adressent à la fois aux professionnels et aux particuliers, avec différentes offres selon les niveaux des besoins et les volumes de données.
Pour les petits corpus nous faisons un traitement à la page. Pour les corpus avec des graphies complexes ou d’autres spécificités nécessitant le développement de modèles sur mesure (p. ex. des documents endommagés, des numérisations en basse qualité, etc.), deux scénarios se présentent: Le premier concerne des institutions, des bibliothèques, des entreprises privées et toute entité lucrative ou non-lucrative qui nous demandent de traiter des milliers de pages avec un pourcentage de reconnaissance élevé et un livrable personnalisé. Dans ce cas, nous proposons des prestations sur mesure.
Nous avons également un autre format, le forfait Recherche, qui s’adresse plutôt aux chercheurs travaillant sur un corpus en particulier, qui ont des petits budgets et ne sont pas limités par le temps de sorte qu’ils puissent créer eux-mêmes leurs données sur notre plateforme Calfa Vision (https://vision.calfa.fr), qui est un outil en ligne de transcription et d’annotation de documents sur laquelle tournent plusieurs de nos modèles. L’interface leur permet de charger des images, de transcrire manuellement, d’annoter quelques pages et d’entraîner avec nous des modèles pour traiter efficacement leur corpus.
A.: Quels sont vos projets en cours?
Ch. V.-G.: Nous traitons actuellement la correspondance de la Congrégation des Pères Mékhitaristes de Venise des 18e et 19e siècles. Il s’agit d’un travail philanthropique avec l’objectif d’aboutir à une base de données qui permet de rechercher des informations et tracer l’histoire de la diaspora arménienne par le truchement de ces lettres.
En collaboration avec la Bibliothèque Nationale de France, nous travaillons sur la numérisation et l’indexation du fonds de l’orientaliste Dulaurier composé de manuscrits arméniens copiés ou commandés. L’objectif est d’ici fin 2023 de mettre en ligne sur Gallica ces manuscrits qui représentent un intérêt historique et philologique.
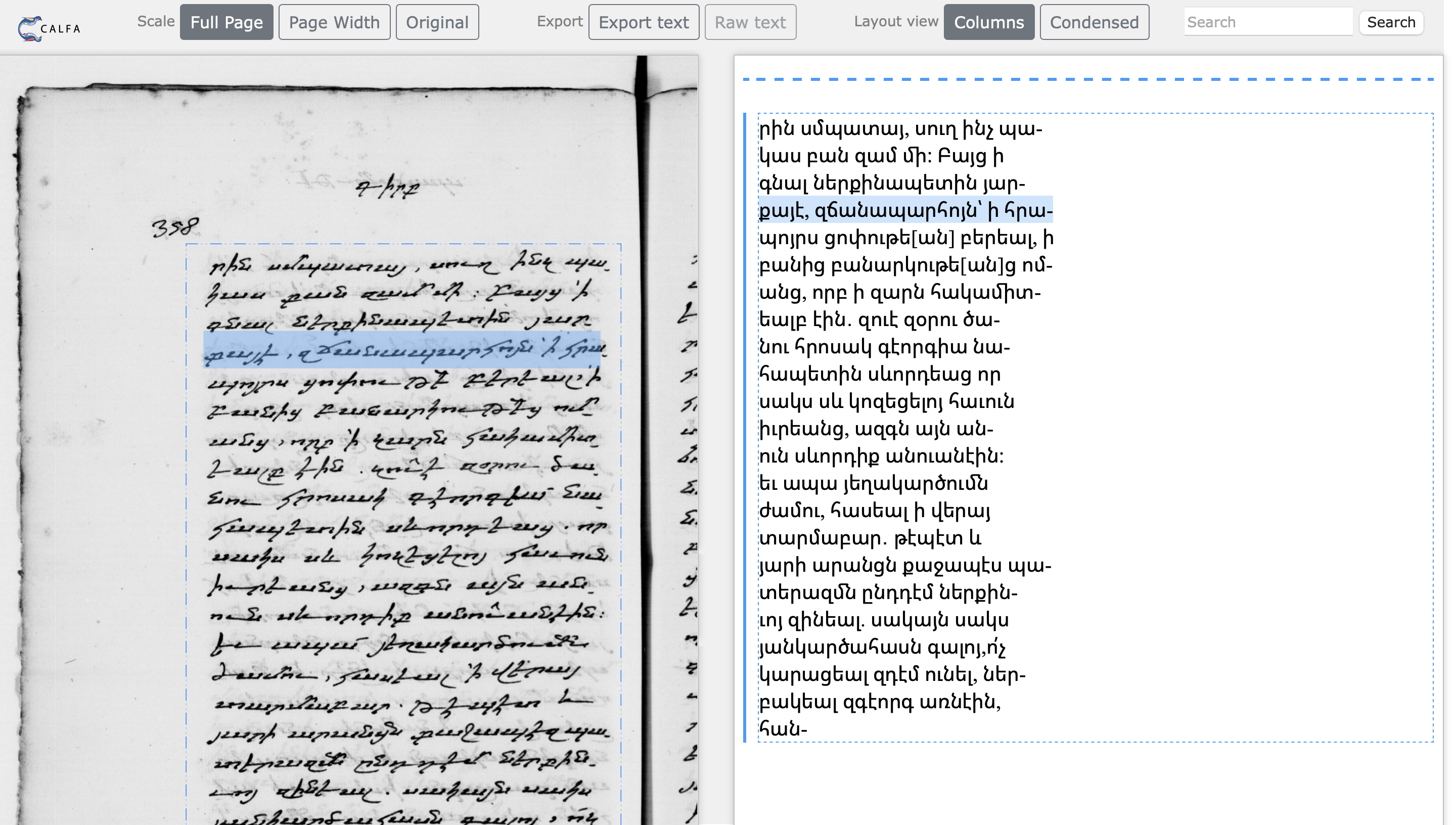
(Fonds Dulaurier)
Un autre projet en cours est le catalogage de la Bibliothèque Nubar de l’UGAB à Paris et la numérisation des fiches bibliographiques manuscrites réalisées par les conservateurs de la Bibliothèque depuis sa création. L’objectif est d’aboutir à une version numérique du catalogue avec identification automatique des informations bibliographiques pertinentes (nom d’auteur, date de publication, etc.).
A.: Quels sont les objectifs de Calfa à long terme?
Ch. V.-G.: L’objectif de Calfa est d’assister les professionnels pour la conservation et la valorisation des manuscrits anciens, archives, carnets et correspondances qui constituent un fabuleux patrimoine, souvent difficile d’accès. Nous travaillons sur les langues rares ou anciennes au patrimoine riche, avec une sensibilité particulière pour l’arménien. Notre but est d’arriver le plus possible à la généricité de nos modèles pour qu’ils soient en mesure de traiter le plus grand nombre de documents possible et d’aboutir à des bases de données interrogeables.
Dans le cadre de nos partenariats avec les institutions patrimoniales arméniennes nous souhaitons nous engager de manière philanthropique afin de rendre ce patrimoine plus accessible au grand public. Nos prestations dans les autres langues telles que l’arabe ou le chinois nous donnent une certaine autonomie, ce qui permet aux membres de notre équipe, chercheurs passionnés du patrimoine arménien, de s’y investir bénévolement.
(Entretien réalisé par M.S.)
…………………………..
(*) Diplômé de l’INALCO (arménien, texte et linguistique), Chahan Vidal-Gorène est actuellement doctorant en paléographie arménienne et vision par ordinateur à l’École Nationale des Chartes-PSL, où il enseigne dans le cadre du Master Humanités Numériques. Ses recherches portent notamment sur le traitement automatique de la langue arménienne et des problématiques liées au patrimoine numérique. En 2019, il a obtenu pour son projet Calfa le prix Télécoms Innovations « Accès à la culture et au patrimoine par le numérique » de la Fédération Française des Télécoms.